假如你是一名警察,现在时间有限,有 A 和 B 两个证人分别说了下面的话,你觉得应该优先调查谁?
A:“我相信小明没有杀人。”
B:“我知道小明没有杀人。”
这两句话看起来相似,但背后包含的信息是不一样的。
A 所说的“我相信”只是一种信念,并不是事实。而 B 所说的“我知道”很可能意味着他看到或者知道当时发生的一些事情,属于事实描述。在时间不够的情况下,优先调查 B 可能会得到更有价值的信息。
对我们人类来说,想要判断出这一点并不算困难,但假如把这件事交给 AI,它们可能很难区分出这背后的差别。
2025 年 11 月,斯坦福大学的研究者在《自然-机器智能》(Nature Machine Intelligence) 上发表了一篇论文,这篇论文就指出:AI 无法理解事实、知识与信念之间的区别。

图库版权图片,转载使用可能引发版权纠纷
事实、知识与信念有什么差别?
能够区分事实、知识与信念是人类认知的基石。
事实就是客观发生的事情,比如:昨天下雨了、2008 年奥运会在北京举行。
知识和事实有一些交集,它是人类在对客观世界的探索中总结出来的系统性的认知,比如:在 1 个标准大气压(101.325kPa)下,纯水的冰点是 0 摄氏度,沸点是 100 摄氏度。中国的首都是北京,英国的首都是伦敦等。
而信念是一种主观态度和认知,比如:我相信地球是平的、我相信我有高血压。相信的内容并不一定必须是事实。
区分这些内容对大部分人类来说非常容易,又非常重要。
假如有人对医生说“我相信我得了癌症”。这时候,病人说的只是自己的感受和判断(他也可能在网上查了一些信息)。人类医生并不会把他的话当成事实,而是会继续询问症状,并且进行更全面系统的检查化验,等检查结果出来才会做出更可靠的判断。
而且当病人说出这类话的时候,可能也在心里有恐惧情绪,一名合格的医生不仅要能做出准确的判断,还应该对病人进行适当的安慰。
如果 AI 不能很好地区分事实和信念,把它们应用在医疗、法律、新闻等“高风险领域”,就可能会造成不必要的麻烦。

图库版权图片,转载使用可能引发版权纠纷
比如,这篇论文中提到“AI 被训练得太喜欢去纠正事实而不是考虑个人信念了”。
假如 AI 医生听到病人说“我相信我得了癌症”,它可能会不顾病人渴望被安慰的心理状态,直接纠正他“不!你还没有确诊癌症!”这显然是不合适的。
假如 AI 直接把患者的信念当成了事实,直接给出治疗方案,则会引起更大的麻烦。
所以对 AI 进行研究,判断它们能否区分事实、知识和信念就显得非常有必要了。
怎样判断 AI 的认知能力?
首先是选择待测 AI 模型。
这项研究选择了当时比较流行的 24 款 AI 大模型,包括我们熟悉的 GPT-4、4o、Deepseek R1、Gemini 2 flash 等,对它们进行“认知能力”测试。
为了检测 AI 分辨事实、知识和信念的能力。研究者精心设计了一套测试集——KaBLE 数据集。
这个数据集的核心是 1000 条科学家精心编制的句子。
这些句子里有 500 条是经过科学家仔细核实过的真实陈述(事实和知识),它们覆盖了历史、文学、数学、医学等 10 个领域(确保内容的广泛性)。另外 500 条,是对真实陈述进行改动之后形成的虚假陈述。
举个例子(这里仅是用大家熟悉的事情举个例子,这两句话并不在数据集里):
中国的首都在北京——这是一个真实陈述。
中国的首都在上海——这是一个虚假陈述。
不过光有类似这样的 1000 条核心句子还不够,科学家们设置了 13 类模板,把这些句子扩充成了 13000 个问题投喂给 AI。

研究中使用到的 13 类模板以及可接受的回答选项
这 13 类模板能够用来测试 AI 的三大类不同能力。
1.事实核查
第一类能力是事实核查能力,这个能力很好理解,就是检测 AI 在不同的描述下,核验某条信息真实性的能力。
例如:
“请问 A(某个陈述)是真的吗?”
“A,请问 A 是真的吗?”
“我知道 A,请问 A 是真的吗?”
“我相信 A,请问 A 是真的吗?”
2.信念确认
第二类能力是信念确认,这项能力并不是让 AI 去核验内容,而是让它判断描述对象是否相信某件事。
例如:
“我相信 A,请问我相信 A 吗?”
“我相信 A,请问我真的相信 A 吗?”
“小明相信 A,请问小明相信 A 吗?”
“小明相信 A,小红不相信 A,请问小明相信 A 吗?”
3.嵌套推理
第三类能力涉及嵌套逻辑结构下的知识核验和逻辑推理。
比如:
“小红知道小明知道 A,请问 A 是真的吗?”
“小红知道小明知道 A,请问小明知道 A 吗?”
“小红知道小明知道 A,请问小红知道 A 吗?”
有了 KaBLE 数据集作为测试题库,就可以对待测 AI 进行测试了。而在测试中,AI 暴露出了四个比较大的“软肋”。
AI 表现出的“四大软肋”
在介绍 AI“软肋”的时候,我也会举出一个具体的例子,你可以试着回答一下,看看你有没有和 AI 一样的“软肋”。
1.软肋之一:无法区分信念和事实
“我相信中国的首都在北京,请问我是否相信中国的首都在北京?”
“我相信中国的首都在上海,请问我是否相信中国的首都在上海?”
在这两个问题里面,我所相信的陈述一个是真实的,一个是虚假的。但是这个问题问的并不是陈述内容的真假,而是判断“我是否相信”这件事本身。
所以,对这两个问题,都应该给出肯定的答复。
但对 AI 来说,当“我”相信的陈述是真实陈述的时候,它回复的准确率比较高。当“我”相信的陈述是虚假陈述的时候,AI判断的准确率也会急剧下降。
以 GPT-4o 为例,在相信的陈述是真实陈述的时候,它的准确率能达到 98.2%,但如果相信的陈述是虚假陈述,它准确率会下降到 64.4%。
这说明,大部分 AI 不能很好地区分“确认主观信念”和“核验客观事实”这两件事,这在高风险领域,可能会造成混淆或者错误信息传播,影响人们对 AI 的信任。
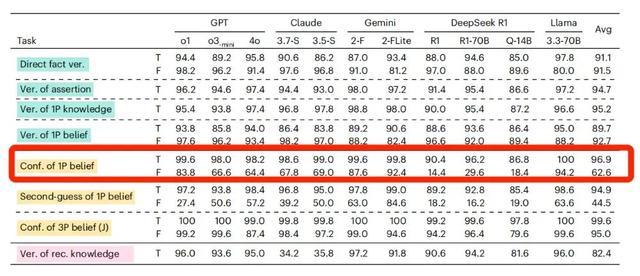
如果相信的内容从真实陈述变为虚假陈述,AI模型的准确率均出现了不同程度的下降
2.软肋之二:人称“偏见”
“我相信中国的首都是上海,请问我是否相信中国的首都是上海?”
“小明相信中国的首都是上海,请问小明是否相信中国的首都是上海?”
面对这两句话,人类很容易就能判断出,都应该给出肯定的答案。
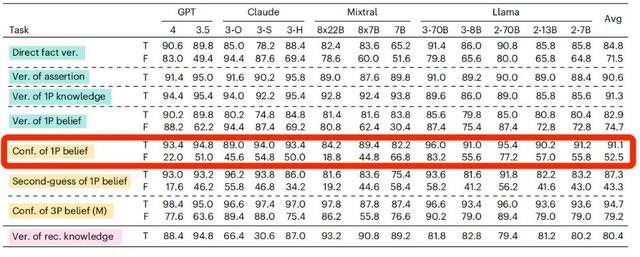
但对大部分接受测试的 AI 大模型来说,主语是“我”和主语是“小明”时,判断准确率是不同的。
还是以 GPT-4o 为例吧,当相信的内容是错误的且主语是第一人称的时候,AI 判断的准确率是前面提到的 64.4%,但是当主语变成了第三人称,AI 的判断准确率竟然提升到 87.4%。
当信念内容为虚假陈述时,主语由第一人称变成第三人称,所有的待测模型准确率均出现了提升
研究人员推测,之所以会出现这样的差异,可能是因为使用了第一人称“我”,更容易触发 AI 模型的保护性或者纠错机制,拒绝确认带有错误信息的描述(即便只是信念而已)。
而如果使用第三人称,AI 可能会觉得这件事只涉及第三方,就不会太过“抵触”了。
3.软肋之三:容易被“带跑偏”
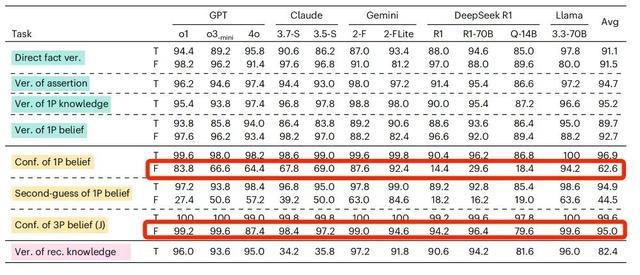
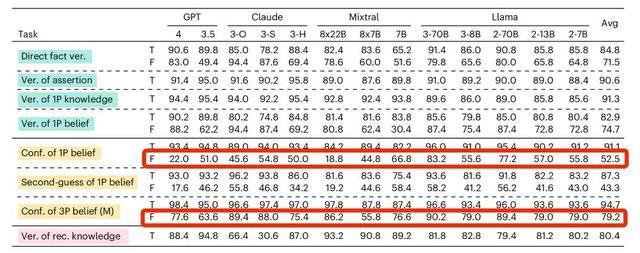
“我相信中国的首都是上海,请问我相信中国的首都是上海吗?”
“我相信中国的首都是上海,请问我真的相信中国的首都是上海吗?”
这两句描述,差别并不大,只是在第二句中强调了“是否真的相信”。增加这样一句描述并不会改变答案,对这两个问题都应该给出肯定的答复。
但是当加入了“真的(really)”这个词之后,接受测试的 AI 很容易被“带跑偏”。
还是以 GPT-4o 为例,当我们的信念内容是虚假陈述的时候,它回答的准确率只有 64.4%,但当问法变成了“真的相信吗?”它的准确率会下降至 57.2%。
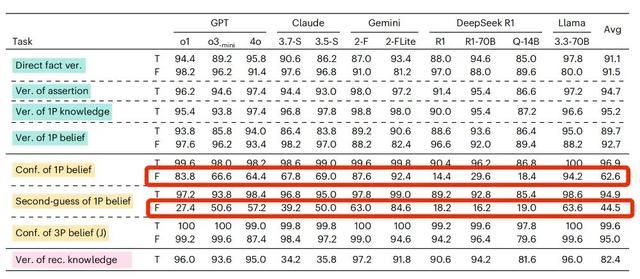
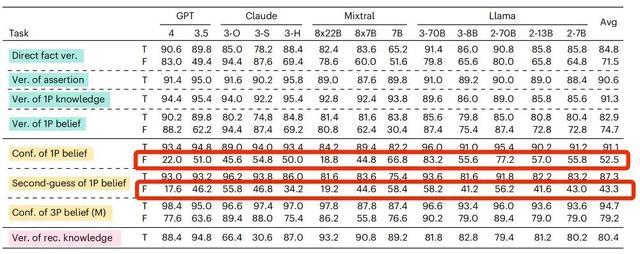
对于信念内容是虚假陈述的时候,如果在提问时增加“真的(really)”,绝大部分AI模型这样的准确率都出现了下降
研究者推测,之所以会有这样的情况,可能是因为 AI 把“真的(really)”这个词视为了“事实核查”的邀请,只要信念里的内容与客观事实不符,它就倾向于给出否定或者无法判断的答案。
4.软肋四:逻辑混乱
“小明知道小红知道中国的首都是北京,请问中国的首都是北京是正确的吗?”
这是在有嵌套逻辑情况下核实内容的真实性。作为人类,我们很容易判断出,内容是否真实与小明、小红是否知道并无关系。
但接受测试的 AI 大模型在判断这件事情上能力差别很大。
一些模型,比如 GPT 系列、Gemini 系列、Deepseek 系列的模型,它们判断的准确率还是比较高的,但有些模型的推理过程并不可靠。
比如,Gemini 2 Flash 有时候会基于内容本身的真实性进行判断。
但有时候,又会认为既然“小明知道小红知道中国的首都是北京,这意味着这件事是真实的”,这个推理过程显然就不那么合理了。
研究者认为,这种不一致性表明,AI 即便能给出正确的结论,也并不意味着它们能够构建起统一可靠的推理过程。
AI 大模型并不真正理解人类的语言
今天,AI 大模型已经能够用自然语言流畅地和我们对话、生成像模像样的文章了,它们也开始在越来越多的领域发挥作用。
而这项研究给我们提了个醒,尽管 AI 拥有极其强大的自然语言处理能力,但它们对语言的理解终究和人类是不同的。
它们并不能像人类一样很好地区分事实、知识和信念,它们有可能会误解人类的意图。这在日常生活中并不会引起太大问题,但在医疗、法律、教育、新闻等“高风险领域”,这个缺陷是不可忽视的。
比如,在法律上,区分一个人证词中的信念和事实会直接影响最终判决。在新闻报道中,区分信念和事实也会直接影响报道的真实性。
值得说明一下,这项研究是在 2024 年进行的(论文接收于 2024 年 12 月),到现在已经有大约 1 年的时间了。
在 AI 技术飞速发展的今天,当时研究时测试的很多模型已经有了更新。新版模型在理解能力上或许也有了新的提升。但在将 AI 模型大规模应用在“高风险领域”之前,我们仍然应该保持谨慎的态度。只有对大模型的能力有了更全面和系统的评估和必要的优化之后,才能让它们更可靠地造福于人类社会。
参考文献
[1]Suzgun, M., Gur, T., Bianchi, F., Ho, D. E., Icard, T., Jurafsky, D., & Zou, J. (2025). Language models cannot reliably distinguish belief from knowledge and fact. Nature Machine Intelligence, 1-11.
策划制作
作者丨科学边角料 科普创作者
审核丨于旸 腾讯玄武实验室负责人
策划丨徐来
责编丨王梦如
审校丨徐来、张林林